丸レク3(丸山先生レクチャーシリーズ 2010 第3回)に行ってきた。
丸レク3に行ってきた。一ヶ月くらい前に…。
今更だけど、頑張って思い出していろいろ書いてみる。
基本的には出来損ないのメモがベース。字が判別不可能なくらい小さいので、大きなメモはflickrでどうぞ。
でもUstの録画があるから、いざとなればそっちを見ればいいと思う!すごく重たいエントリになったけど、まあ仕方ない。
今回はKey-valueストアの話が多かった。
僕はkey-valueストアにあまり詳しくなかったので、知らなかったことがいろいろあって面白かった。
Google App Engine で datastore と memcache をちょっと触ったことがあるくらいで、NoSQL が Not Only SQL と最近解釈されていることは知らなかったくらい。
このエントリが長くて細かくて読んでられん、後で読む、って人は Togetter - まとめ「丸レク2010楽天タワー」 を先に読むといいかも。
並列と分散 - 丸山 不二夫さん
http://www.ustream.tv/recorded/6353240
http://www.ustream.tv/recorded/6353512
資料はこちら。http://maruyama.cloud-market.com/download/No3Dist.pdf
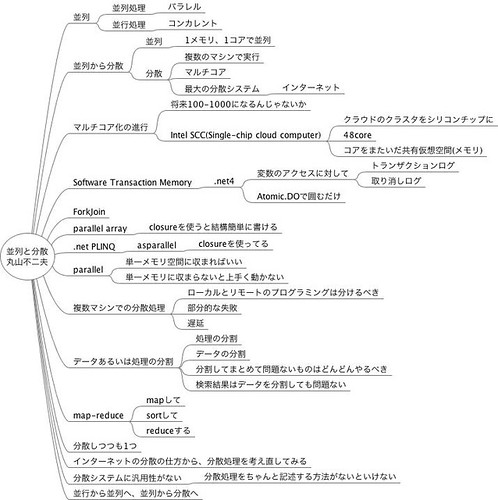
丸山先生のセッションは、内容が多すぎてとてもメモしきれない。
でもその分資料にほとんど書いてあるので、あとから見返すことができる。
印象的だったのは、並行、並列、分散という言葉。それぞれ Concurrent, Parallel, Distributed.
正直なところ、いろいろ難しくてわからないことも多かった。
セッション資料の106ページ以降がまとめ的な章になっているので、これを読むと分かった気分になれるかもしれない。
資料の114ページが結構わかりやすかった。
- 並行処理は Single Machine
- 並列処理は密Cluster, Multi-Core
- 分散処理は Cloud, MapReduce
- 超分散処理は Internet, Communication
並行から並列へ、並列から分散へ。
key-valueストアの基礎知識 - 首藤 一幸さん
資料はこちら。http://www.shudo.net/publications/key-value-store-20100422/
首藤さんのエントリはこちら。懇親会が楽しそう。http://www.shudo.net/diary/2010apr.html#20100422
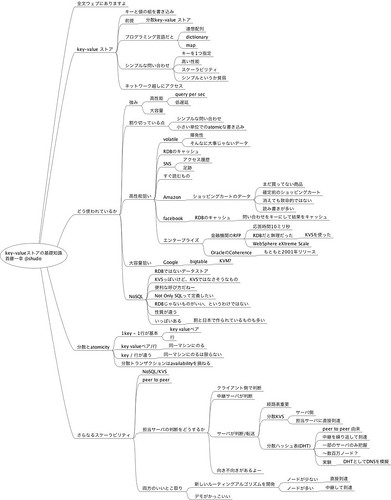
Ustがないのが残念だけど、資料がきっちり公開されているのでよかった。
こんなよい資料が公開されているなんていい時代だ。
タイトルそのままだけど、Key-Valueストアの基本的な内容がしっかり書いてあって分かりやすかった。
このセッションのお陰で、この後の内容がわかりやすくなった。
Key-Valueストアという言葉を初めて聞いた、というひとにもお薦めの資料だと思う。
GREEのパフォーマンスとスケーラビリティ戦略 - 藤本 真樹さん
http://www.ustream.tv/recorded/6354721
資料はこちら。http://prezi.com/xhxsyxmjf3zn/2010-3-fujimoto/
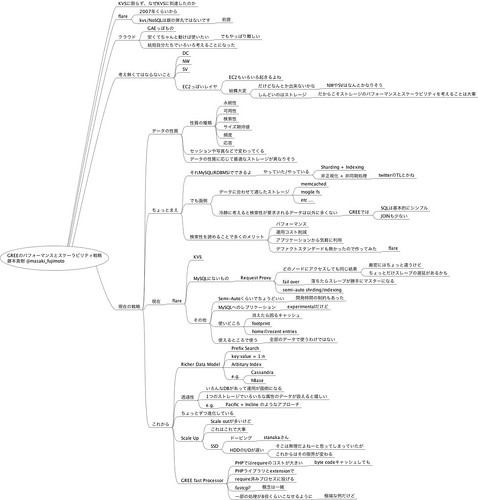
資料がぐるんぐるん動いていて面白かった。
技術的な話題は少なめで、Greeがどのようにスケールしていったのか、ということが中心だった。
Key-Valueストアは銀の弾丸ではなく、使い所が大事。使い所とはデータの性質によるもので、例えば 永続性 / 可用性 / 検索性 / サイズ期待値 / 頻度 / 応答速度 など。
これらの性質に応じて適切なストレージは異なる。
こういったことは、なんとなく分かるし、なんとなく想像できそうなものだけど、実際に体験した人から聞くとやっぱり実感があって違うなぁと感じた。
あとは「SSDはドーピング」というフレーズが印象的だった。
分散Key-valueストアkumofsの思想と設計 - 古橋 貞之
http://www.ustream.tv/recorded/6355094
資料はこちら。
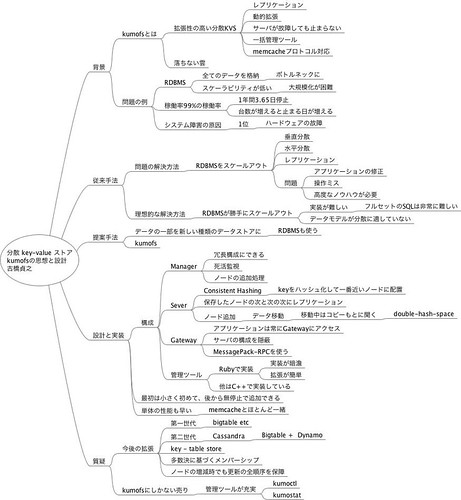
個人的にはこの日いちばん面白かった。
それは分散Key-Valueストアのことをほとんど知らなかったからだと思う。
また資料がとてもよくまとまっていて、わかりやすかったし、かっこよかった。かっこいいって大事。
とにかく止まらない。がんがん落としても止まらない。すごい。
そんなわけで、詳しく知りたければ資料とustをどうぞ。
楽天インターネットスケーラブルコンピューティング - 吉岡 弘隆さん
http://www.ustream.tv/recorded/6355739
資料はこちら。
楽天がどのようにトラフィックに対応してきたのかがわかる。
最初は All in One な1台のサーバから始まって、Web-ApDBの2層に分かれ、ロードバランサとデータ分割が行われ、NASが導入されWeb-AP-DBの3層構造になり、ストレージにSANが導入される。
その後、スレーブDBが追加され、データセンタ間の相互バックアップが行われ、キャッシュサーバやCDNが導入された。
こういった内容や、さらにその後どうやって対応していったのかということが主な内容だった。
吉岡さんのエントリには「特に技術的に目新しいことではなく、楽天のWebサービスのインフラの歴史とか、どんな感じで日々のトラフィックをさばきながら発展していったかという実に地味なお話であった。」と記載されていた。確かに裏方の話ではあるが、全然地味ではないし、とても面白かった。
-
-
- -
-
全体的にスーツな人たちが多かった。僕もだけど。
twitterはそれなりに盛り上がっていたと思うが、blogのエントリなどはあまり見かけない。
でもどのセッションもはずれがなく、とても興味深い内容だった。
参加できなかった人は、セッション資料だけでも見てみると良いと思う。
Key-Valueストアの経験値が大分上がった一日だった。